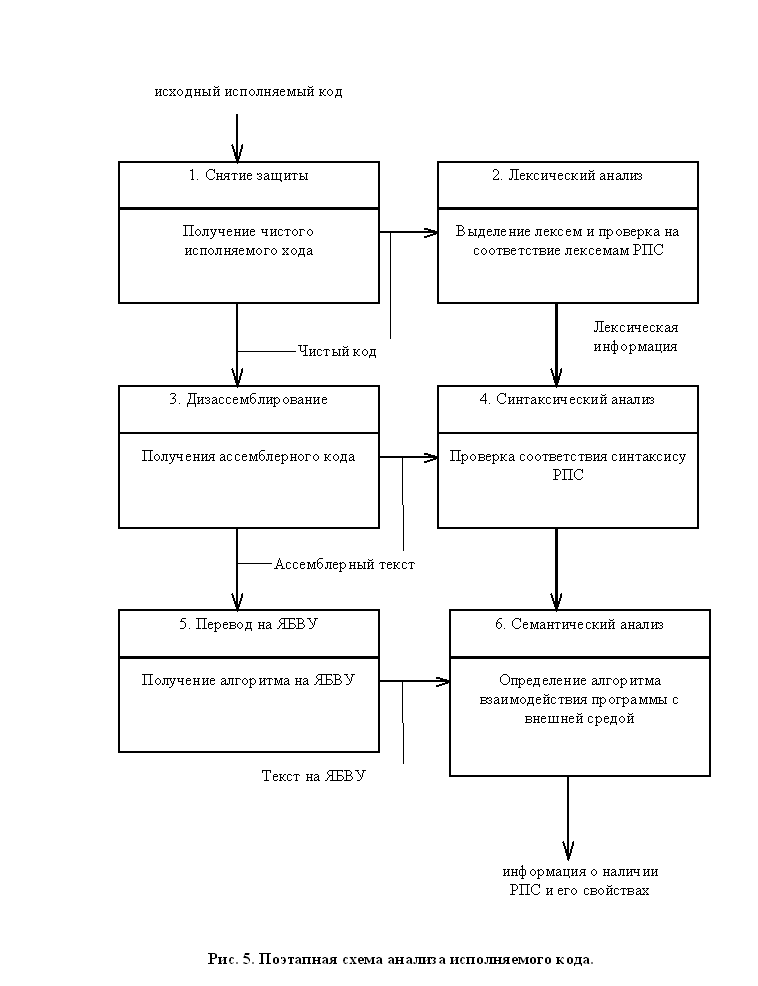
При анализе программ на любом языке обязательно присутствуют три этапа (цифры соответствуют рис. 5 и рис. 8):
2) лексический анализ;
4) синтаксический анализ;
6) семантический анализ.
Первые два из них обычно осуществляются автоматически (например, компиляторами), а семантику отслеживает человек. В этой главе мы попытаемся применить эту схему и к анализу программ в исполняемом коде, хотя точной аналогии между понятиями, существующими в теории компиляторов и вводимыми здесь, провести нельзя.
Каждый из этих этапов также требует предварительной подготовки:
1) выделение чистого кода — удаление кода, отвечающего за защиту этой программы от несанкционированного запуска, копирования и т.п. и преобразование остального кода в стандартный, правильно интерпретируемый дизассемблером. Как частные случаи, это может быть разархивация, расшифровка кода;
3) дизассемблирование — перевод команд на язык ассемблера;
5) перевод в форму, удобную для следующего этапа — выделение основных процедур, циклов и др. управляющих конструкций, основных структур данных, а также, возможно, перевод на язык более высокого уровня (ЯБВУ);
Таким образом, общая поэтапная схема анализа программ будет выглядеть так (рис. 5):
Задачей первого этапа анализа исполняемого кода программ является подготовка его к этапу лексического анализа и дизассемблирования. Можно назвать две основные причины, по которым исполняемый код может быть затруднен для дизассемблирования. Это:
1) специально предпринятые меры для противодействия исследованию этого кода. Такой код будем называть защищенным, а алгоритмы, их реализующие — системами собственной защиты программ.
2) меры, направленные на преобразование кода в другую форму и не преследующие задачи противодействия. Чаще всего это архивация или шифрация исходного кода. (Шифрация может применяться и с полезными целями: например, преобразование кода так, чтобы он состоял только из печатаемых символов — это необходимо для пересылки его по каналам электронной почты). Для простоты такие алгоритмы тоже будем называть системами защиты.
Таким образом, преобразованный код будет состоять из процедуры защиты (дешифровки) и защищенной (зашифрованной) части, а алгоритмам, отвечающим за восстановление чистого кода, необходимо проделать обратные действия:
удалить систему защиты и
преобразовать оставшийся код в стандартный.
Здесь мы сталкиваемся с той же проблемой: чтобы удалить систему защиты, надо понять, как она работает, т.е. провести семантический анализ ее алгоритма.
Однако, если ввести ограничение (справедливое для большинства защит и упаковщиков программ), что система защиты не включается в программу на этапе ее разработки, а внедряется в уже готовый исполняемый файл (также, как и вирусы), то анализа системы защиты возможно избежать и автоматизировать восстановление исходного кода с помощью т.н. "универсальных распаковщиков" (блок 9.5 на рис 8). Это следует из того, что в этом случае система защиты отрабатывается сразу, при любом наборе входных данных. И после ее отработки можно снять дамп памяти, содержащий уже расшифрованный код.
Здесь возникает всего две проблемы:
а) как определить, что система защиты уже отработала, т.е. найти начало "чистого" кода. Оказывается, что это не так трудно сделать, в частности, начальный код, генерируемый любым компилятором, стандартен и известен.
б) определить размер снимаемого дампа (в случае архивации он может быть даже больше, чем начальный размер программы). Здесь тоже существуют некоторые эвристические методы, но в крайнем случае ничто не мешает взять некоторый максимальный размер.
Для системы MS DOS известно много "универсальных распаковщиков" (UUP, Intruder, AutoHack), позволяющих не просто получить код в виде дампа памяти, а обычный нормально запускающийся EXE-файл. Не вдаваясь в подробности, заметим, что для генерации EXE-файла необходимо еще и определить, какие данные относятся к таблице перемещения и восстановить ее. Это достигается тем, что исходная программа запускается два раза с разных адресов и данные, корректируемые таблицей перемещения, в двух разный дампах оказываются неодинаковыми.
Если же система защиты не является такой простой, то в этом случае на помощь могут прийти трассировщики (блок 9.2 рис. 8)[6]. Они записывают каждую инструкцию, проходящую через процессор (т.е. содержимое ячейки, на которую указывает IP) в специальную область памяти или файл, совершенно "не вникая", путем каких преобразований была получена эта инструкция, запоминая таким об разом список действительно исполняемых команд, трассу (trace).Очевидность этого метода следует из того, что любая система защиты должна восстановить исходный код по крайней мере в момент считывания его центральным процессором. Однако трассировщики применимы только тогда, когда система защиты не включает и динамическую защиту. В противном случае она может распознать изменения, вносимые трассировщиком в вычислительную среду.
Получаемый трассировщиком код, конечно, не очень похож на компилированный, однако в нем можно автоматически выделить процедуры, циклы и т.п., сократив его в десятки раз. Это можно делать как сразу, по мере получения трассы, так и потом, работая уже с готовой.
Если же в результате этого этапа не удалось получить стандартный код, это уже может служить основанием для отнесения входной программы к подозрительным, т.к. она использует весьма сложную систему защиты, что подавляющему большинству полезных программ явно не нужно.
(Пока не введены определения последующих этапов, необходимо заметить, что они появятся автоматически, как только будет дано определение лексемы. Весь излагаемый материал строится на аксиоме, что лексемой является сигнатура РПС, но совершенно не лишены смысла и другие ее определения. Например, вполне возможно ввести как лексему машинную команду).
Согласно [17], лексический анализ — это процесс распознавания транслятором во входном тексте смысловых единиц (лексем): идентификаторов, чисел, операторов и т.п. По аналогии, лексическим анализом при исследовании исходного кода программ будем называть процесс поиска и распознавания лексем, которыми в данном случае будут являться определенные регулярные последовательности, называемыми сигнатурами РПС (блок 8.1 рис. 8).
Определение сигнатуры РПС отличается от определения сигнатуры вируса и звучит как: "Сигнатурой РПС называется любая регулярная последовательность байт, встречающаяся в исполняемом коде РПС". Таким образом, сигнатуры вирусов — это частный случай сигнатур РПС.
Функцией лексического анализатора, несколько выпадающей из общей схемы анализа, является т.н. "экспресс-анализ" (блок 2.1 рис. 8) — поиск сигнатур известных РПС, нахождение которых однозначно свидетельствует, что программа содержит "вредный" код (т.е. той или иной РПС), и в этом случае не требуется дальнейшего исследования.
До сих пор именно лексический анализ являлся основным и очень эффективным средством поиска вирусов (см. п. 1.1.1). Это связано с весьма большим быстродействием и простотой в реализации, позволяющей также исправлять и наращивать базу искомых сигнатур. Именно эти характеристики позволяют применять лексический анализ в качестве начального этапа анализа исполняемого кода — "экспресс-анализа".
Рассмотрим подробнее, какого вида регулярные последовательности можно применять для этом этапе для наиболее полного и эффективного поиска разных классов РПС.
Самым простым их видом являются последовательности байт определенной длины или т.н. простые байтовые сигнатуры. Они могут записываться в десятичном, шестнадцатиричном, двоичном или символьном виде, а алгоритмы их поиска эффективны и широко описаны [18].
Однако не все вирусы и другие РПС имеют такие сигнатуры. В частности, многие вирусы часто вставляют в свой код некоторое переменное число байтов, чтобы довести размер зараженной программы до числа, кратного 16 (округление по границе параграфа). Далее, в теле вируса могут быть неизвестные заранее последовательности байт определенной длины, попадающие в него из заражаемой программы (например, первые байты из начала заражаемой программы).
Наличие таких фрагментов в разных местах тела вируса, с одной стороны, резко уменьшает длину максимальной байтовой сигнатуры и, с другой, увеличивает число таких сигнатур, каждую из которых можно использовать для поиска вируса. Конечно, для осуществления поиска любых вирусов, имеющих сигнатуру, в принципе можно было бы использовать и такие короткие простые байтовые сигнатуры, но для увеличения длины сигнатуры и, соответственно, существенного повышения качества диагностирования, вводятся так называемые регулярные сигнатуры.
Эти более сложные сигнатуры можно искать, применяя широко известные регулярные выражения, отсюда их название. Эти сигнатуры являются расширениями простых байтовых сигнатур с помощью двух специальных символов: '*' и '?'. Первый означает любое количество (0 и больше) байт, а второй строго один байт. Таким образом, сигнатура
EB ? ? FF * FF
может означать
EB 10 00 FF FF
EB FF FF FF FF FF
и т.д.
К сожалению, мысль создателей РПС с точки зрения их маскировки пошла дальше. Сначала появились вирусы, самошифрующиеся с переменным ключом. Очевидно, что для такого вируса в качестве сигнатуры может выступать только фрагмент незашифрованного кода, т.е. расшифровщик, который обычно представляет собой очень короткую последовательность байт, что ухудшает качество их диагностирования. Но потом появились вирусы, вообще не содержащие ни простых, ни регулярных байтовых сигнатур — так называемые вирусы с самомодифицирующимся расшифровщиком. Это вирусы, использующие помимо шифрования кода, специальную процедуру расшифровки, изменяющую саму себя в каждом новом экземпляре вируса. Достигается это за счет того, что один и тот же алгоритм можно реализовать большим количеством способов на конкретном языке. Например, в машинных кодах (т.е. в исполняемом коде) можно:
1) добавить к нему ничего не значащие команды;
2) поменять используемые регистры;
3) переставить команды местами.
Для поиска таких вирусов пришлось применить новый тип сигнатур: битовые регулярные сигнатуры. Первый способ изменения кода легко обходится использованием уже известного символа '*', который имеет здесь тот же смысл, что и выше: 0 или более байт. (Отметим, что именно байт, а не бит, т.к. вряд ли существует машинный язык, на котором команды имели бы переменное число бит). Второй способ — чередование используемых регистров — описывается введением битового символа '?', означающего битовый 0 или 1. Дело в том, что регистр, используемый в команде, кодируется либо в каком-то конкретном байте этой команды (и тогда можно применять более эффективный символ '*'), либо в конкретных битах команды, а остальные биты остаются постоянными. (Для MS DOS справедлив второй случай). Третий способ — чередование команд местами — может быть обойден введением асинхронных выражений, выделяемых символами начала '{' и конца '}'. Все группы байт, попадающих в эти выражения, могут быть переставлены местами во входной последовательности. Регулярная битовая сигнатура и ей соответствующая последовательность представлены на рис. 6:

Однако в 1992 г. появились вирусы, для поиска которых непригодны даже регулярные битовые сигнатуры! Это все те же вирусы с самомодифицирующимся расшифровщиком, но использующие очень совершенный алгоритм такой самомодификации, называемый MtE (Mutant Engine). В нем, помимо приведенных выше способов мутации, применяется еще и четвертый:
4) использование других команд (xor ax, ax вместо mov ax, 0; push/ret вместо jmp и т.д.).
Расшифровщик, сгенерированный по этому алгоритму, не имеет ни одного постоянного бита, а используется в нем более половины всех инструкций процессора 8086. Таким образом, лексический поиск для таких вирусов просто неприменим (см. п. 1.1.1).
Вместо регулярных битовых сигнатур гораздо более удобно использовать регулярные ассемблерные сигнатуры, являющиеся их расширением. Они избавляют пользователя от необходимости перевода вручную самомодифицирующегося кода в регулярные битовые последовательности. Их элементами являются ассемблерные команды и расширенные регулярными выражениями, состоящие из префикса и регулярного символа. В качестве префикса могут выступать: x, l, h — означают регистр, его младший и старший байт соответственно;
s — сегментный регистр;
c — команду;
o — операнд;
a — адрес;
без префикса — всю команду.
К регулярным символам добавились, помимо '*' и '?', цифры, означающие конкретный объект. Например, x1 означает любой (но один и тот же в данном регулярном выражении) регистр.
Символ '*' применяется только к целой команде и не имеет префиксов.
Приведем примеры таких сигнатур:
1)
mov x1, ax cmp x1, 4B00h je 070
Эта конструкция означает присваивание в любой регистр регистра AX, а затем сравнение именно этого регистра с числом 4B00h и переход по конкретному относительному адресу.
2) c? o?, 15FEh
Это — любая двухоперандная инструкция с числом 15FEh.
3)
{ mov x1, a?
mov x2, 100h
}
a1: xor byte ptr cs:[x1], o?
{ inc x1
*
dec x2
}
*
cmp x2, 0
jne a1
Пример очень простого самомодифицирующегося расшифровщика.
Регулярные ассемблерные сигнатуры реализованы переводом их в регулярные битовые последовательности, расширенные символами i, j,... r для конкретных регулярных символов 0..9. Первый пример переводится в следующую последовательность:
10001011 11jjj000
00111001 11jjj000 01001011 00000000
01110100 01110000
Дальнейшим расширением регулярных сигнатур могли бы служить так называемые макрокоманды. Например, макрокоманда
MOV ah, 25h (записывается большими буквами)
означает любую последовательность команд, приводящую в конечном счете к присваиванию в регистр AH числа 25h, причем манипуляции с другими регистрами, памятью и т.п. здесь нас не интересуют. Ясно, что подходящих регулярных последовательностей команд может быть бесконечно много, например:
1) mov ah, 25H
2) mov ax, 2513H
3)
mov h1, 25H
*
xchg ah, h1
4)
mov ah, 20h
*
add ah, 5h
5)
push 2513
pop ax
Однако здесь, также как и при реализации транслятора, необходимо найти разумный компромисс между лексическим и синтаксическим анализом и не перекладывать задачи первого на второй и наоборот. Поэтому поиск макрокоманд вряд ли необходим в лексическом анализаторе. (По крайней мере, без средств динамического исследования он не может быть реализован).
Дизассемблированием называется процесс перевода программы из исполняемых или объектных кодов на язык ассемблера.
Задача дизассемблирования практически решена и не будет поэтому здесь рассматриваться. Для MS DOS существует много хороших дизассемблеров, почти стопроцентно справляющихся со стандартным кодом. (Дизассемблированный текст может считаться 100% правильным, если при повторном ассемблировании получается исходный код. Аналогично, код считается 100% стандартным, если дизассемблер получает 100% правильный текст).
С помощью этапа дизассемблирования поэтому можно проверить качество выполнения этапа получения чистого кода если дизассемблер не генерирует 100% правильный код, то тот этап был не закончен.
В системе анализа исполняемого кода программ однако удобнее применять не стандартные дизассемблеры, а специализированный (блок 8.2 рис. 8), который, помимо ассемблерного текста, может выдавать и другую полезную информацию. Самой важной для следующего этапа будет информация о передаче управления в программе, т.е. последовательность вызова процедур.
Синтаксическим анализом при проектировании компиляторов называют процесс отождествления лексем, найденных во входной цепочке, одной из языковых конструкций, задаваемых грамматикой языка. Иначе его можно рассматривать как процесс построения дерева грамматического разбора. По аналогии будем говорить, что синтаксический анализ исполняемого кода программ состоит в отождествлении сигнатур, найденных на этапе лексического анализа, одному из видов РПС.
Для синтаксического анализа любого языка необходимо иметь его грамматику, описывающую, по каким правилам из лексем (терминальных символов или терминалов) строятся его предложения. Т.е., применительно к РПС, мы должны формализовать "грамматику" РПС, описывающую, по каким правилам из лексем (сигнатур РПС) строятся "предложения" (т.е. различные типы РПС). Это можно сделать с помощью любой формы записи грамматики, например БНФ. Но т.к. грамматика является очень простой и не содержит, в частности, рекурсии, то нагляднее всего отобразить ее в виде дерева, которое будем назвать грамматическим деревом или деревом свертки (рис. 7):
Уровень 0 представляет собой конкретные типы РПС, на уровне 1 они раскрываются достаточно общими функциями, описывающими их алгоритм, на уровне 2 каждая из этих функций конкретизируется функциями более низкого уровня и т.д. до уровня N, где появляются сигнатуры. Таким образом, уровни 0..N-1 содержат нетерминалы, а уровень N — терминальные символы.
Если бы существовала полная аналогия между анализом программ в исполняемом коде и компиляцией, то на этом этапе анализ программ мог быть закончен, т.к. входная цепочка лексем (исполняемый код) должна была бы быть либо принята синтаксическим анализатором (РПС присутствует), либо отвергнута (РПС нет). Однако при компиляции программ цепочка задается абсолютно строго: известны ее длина, порядок следования терминальных символов и т.п. Так же строго задается и грамматика входного языка.
При анализе исполняемого кода это не так:
могут быть не распознаны некоторые лексемы. Это следует из того, что, как отмечалось (п. 3.1.2), макроассемблерные конструкции могут быть представлены бесконечным числом регулярным ассемблерных выражений;
порядок следования лексем может быть известен с некоторой вероятностью или вообще неизвестен. Передачи управления в программе приводят к тому, что лексемы, стоящие рядом в программном файле, могут исполняться совершенно непоследовательно, и наоборот.
грамматика языка может пополняться, т.к могут возникать новые типы РПС или механизмы их работы.
Таким образом, окончательное заключение об отсутствии или наличии РПС можно дать только на этапе семантического анализа, а задачу этого этапа можно конкретизировать как свертку терминальных символов в нетерминалы как можно более высокого уровня там, где входная цепочка задана строго.
Этот этап выполняется с полученным ассемблерным текстом программы и состоит в нахождении и выделении соответствующим образом управляющих конструкций, таких как: циклы, подпрограммы и т.п.; основных структур данных. В какой-то мере этот этап также уже реализован: в частности, дизассемблер Sourcer ((с) V Communications) выделяет процедуры и некоторые структуры данных еще на этапе дизассемблирования, а для выделения управляющих конструкций служит специальная утилита ASMTool (блок 8.4 рис. 8).
Семантический анализ программы, как уже отмечалось, удобнее всего вести на языке высокого уровня. Однако на сегодняшний день задача о переводе из машинных кодов на язык высокого уровня (дискомпиляции — блок 8.3 рис. 8) не имеет приемлемого решения. Поэтому на данном этапе вполне подходящим языком более высокого уровня мог бы стать специализированный макроассемблер, который был описан в п. 3.1.1. Специализированным он называется в том плане, что нацелен на выделение макроконструкций, используемых в РПС. Не нужно смешивать этот процесс с возможным переводом на язык макроассемблера на предыдущих этапах, т.к. там осуществлялась свертка лексем, а не перевод всего текста.
Семантический анализ программы — исследование программы изучением смысла составляющих ее функций (процедур) в аспекте операционной среды компьютера [19].
Введенное определение существенно отличается от толкования понятия "семантический анализ программ" из [17], поскольку там оно интерпретируется только с позиции транслятора программы с языка высокого уровня. Но перевод программ с языка высокого уровня в исполняемые коды не лишает ее смысла, поэтому такое определение не может претендовать на полноту. Напротив, новое определение подразумевает полное сохранение смысла программы и ее интерпретацию компьютерной системой при любой форме представления. Этот этап должен дать окончательный ответ на вопрос о том, содержит ли входной исполняемый код РПС, и если да, то какого типа. При этом он использует всю полученную на предыдущих этапах информацию, которая, как уже отмечалось, может считаться правильной только с некоторой вероятностью, причем не исключены вообще ложные факты или умозаключения.
Таким образом, формально на этапе семантического должна быть закончена свертка нетерминалов, полученных на этапе синтаксического анализа, в нетерминалы уровней 0, 1, 2. Очевидно, что нечеткость имеющейся информации приводит к появлению на этом этапе некоторой машины логического вывода (блок 10 рис. 8) со всеми присущими ей элементами: форме представления знаний и правил, алгоритмами логического вывода, вероятностными заключениями и т.п.
В целом, задача семантического исследования исполняемого кода программ является очень сложной и нуждается в серьезных исследованиях. Вероятнее всего, что полностью автоматизировать ее будет невозможно.
Как мы видим, оба этапа — синтаксического и семантического анализа — преследуют общую цель: построить дерево грамматического разбора и тем самым закончить анализ кода.
Известно, что при построении компиляторов все методы синтаксического анализа можно разбить на два класса: восходящие и нисходящие. Первые (методы сверху вниз) начинают с правила грамматики, определяющего конечную цель анализа, и пытаются так наращивать дерево грамматического разбора, чтобы его узлы соответствовали синтаксису анализируемой цепочки. Вторые (методы снизу вверх) берут за основу терминальные символы и пытаются их свернуть в нетерминалы все более и более высоких уровней.
Совершенно аналогично, в теории экспертных систем различают два подхода: с прямой цепочкой рассуждений и с обратной. Первые, опираясь на известные факты, пытаются по ним построить умозаключение. Вторые, наоборот, беря за основу некоторую гипотезу, пытаются найти данные для ее подтверждения или опровержения.
Похоже, применительно к нашей задаче, эти пары методов являются разными точками зрения на одно и тоже, и, говоря о взаимодействии методов синтаксического и семантического анализа, мы приходим к двум основным объединенным методам анализа исполняемого кода: нисходящие с прямой цепочкой рассуждений и восходящие с обратной цепочкой рассуждений.
Первые последовательно строят гипотезы, что РПС относится к типу 1, типу 2 и т.д. (т.е. начинает с корня дерева свертки) и постепенно спускаются вниз, на каждом этапе пытаясь опровергнуть или подтвердить свою гипотезу, ища соответствующие сигнатуры. Вторые начинают с терминалов уровня N и постепенно поднимаются вверх, сворачивая их в нетерминалы высших уровней с соответствующими вероятностями.
Можно охарактеризовать эти методы и с другой точки зрения: первые можно назвать методами ведущего семантического разбора (где машина логического вывода является первичной, а синтаксический анализатор помогает ей в подборе фактов), а вторые методами ведущего синтаксического разбора (где первичной будет синтаксическая свертка, которую облегчают вероятностные рассуждения семантического анализатора). К точно таким же выводам приходят авторы в [19], рассуждая с несколько других позиций. Более того, они предлагают как наиболее эффективный и многообещающий метод, основанный на сочетании этих двух, но ведь именно сочетание методов логического вывода привело к созданию машины логического вывода с косвенной цепочкой рассуждений [20], которая объединяет достоинства как первого, так и второго подхода.
Общая структура отражает взаимодействие основных модулей системы анализа, описанных выше, а также управляющих модулей, методов статического и динамического исследования и интерфейса с пользователем (рис. 8). Она несколько отличается от приведенной в [19].
Объект исследования — исполняемый код программы — поступает на входной интерфейс ИСАИПК (13.1) для согласования фактической формы представления входной информации с требуемой формой ее представления для ИСАИПК.
Администратор задач ИСАИПК (7) посредством интерфейса с пользователем (13.2) начинает диалог с пользователем по конкретизации цели исследования. Полученная от него информация дает возможность администратору сделать выбор по передаче управления между подсистемами ИСАИПК. В дальнейшем администратор принимает решения о дальнейших передачах управления, продолжении или прекращении исследования и т.д.
Основные этапы анализа (1, 2, 4, 6) описаны выше. Для своих целей они применяют статические (8) или динамические (9) методы исследования, а семантический анализатор еще и машину логического вывода (10).
По завершению процесса анализа администратор передает управление системе анализа РПС, которая определяет его свойства и заносит в общую базу данных (12.1). Результаты анализа поступают на выходной интерфейс (13.3).
Доведение предложенных в этой главе общих схем системы анализа до программной реализации ИСАИПК на сегодняшний день представляется весьма проблематичным из-за сложности и неоднозначности применяемых в них алгоритмов.
Поэтому в следующей главе мы рассмотрим практическую реализацию некоторой подсистемы ИСАИПК (блоки 2.2, 4, 6, 8.1, 8.2, 10, помеченные '*'), выполняющую, однако, ее основную функцию поиск неизвестных РПС в исполняемом коде программ для операционной системы MS DOS.

